
Local LLM Performance Benchmarks 2026: Qwen, Gemma, and Ministral
February 16, 2026Today I'm investigating Tokens Per Second (TPS), Time to First Token (TTFT), and overall output quality of the local LLM models. I'll be running a series of benchmarks on a Linux VPS (CPU-only) and Apple Silicon (M2 and M4) to gain insights into how Unified Memory Architecture and modern instruction sets impact local AI performance in 2026.
What I learned: CPU vs. Unified Memory Performance
Here is what I learned from this 2026 benchmarking exercise:
- Local models have drastically improved: Last time I checked them (about half a year ago), the quality of the output was suspicious, as was the inference speed. Today's GGUF/llama.cpp-powered inference is significantly more robust.
- The 3B Parameter Sweet Spot: Smaller models (up to 3B parameters) are now certainly okay with quality for most tasks. Maybe my standards are too low, but at least they no longer give me "the capital of Moscow is Russia" when asked "what's the capital of France?"
- Qwen 2.5 is impressive: I'm impressed by the output quality of the 0.5B model for text generation tasks like grammar suggestions.
- CPU-only inference is viable: The inference speed of tiny models on CPU-only machines is surprisingly good.
- Mac Mini M4 is a value king: I did my tests on cloud Mac instances and am now considering getting a Mac Mini. The price/quality ratio for non-Pro versions with high-bandwidth Unified Memory is unbeatable for local LLMs.
- Ministral 3B for Reasoning: Mistral's 3B model was the smallest model that passed my simple reasoning test, though it lagged in creative storytelling.
- The Memory Bandwidth Bottleneck: Long-context ingestion on CPU-only machines is bad. A 2-minute wait for a 14B model to "read" a prompt is a workflow killer. The Mac M4's 5-6 second TTFT keeps the process fluid.
- LM Studio & Memory Management: LM Studio looks to be a solid choice for model management, handling memory pressure robustly even for 14B models on 16GB systems.
The Test Bench
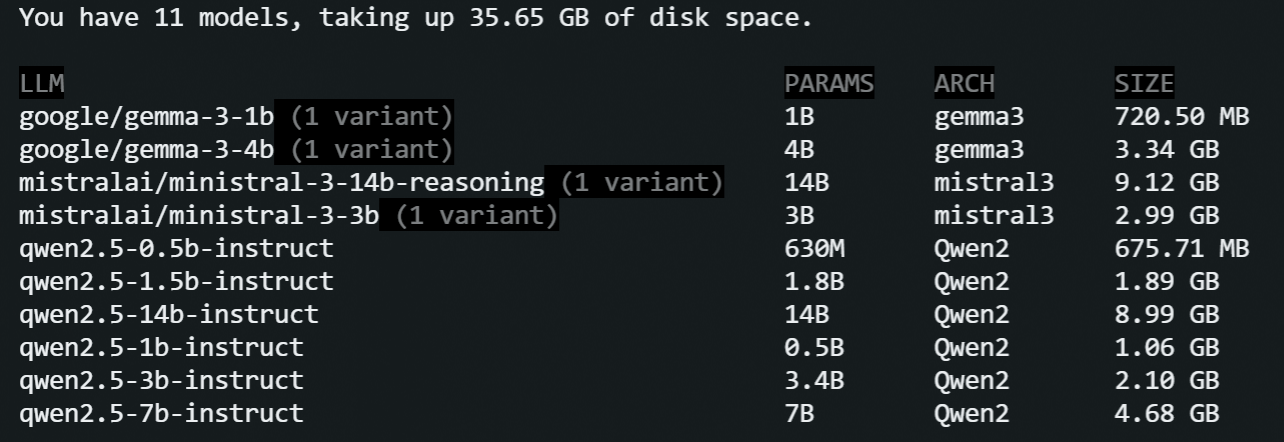
I'm testing GGUF equivalents of the nine models across three hardware configurations and the goal is to measure raw speed (Tokens Per Second), responsiveness (Time to First Token), and logical reasoning capabilities. Models:
- qwen2.5-0.5b-instruct
- qwen2.5-1.5b-instruct
- qwen2.5-3B-Instruct
- qwen2.5-7B-Instruct
- qwen2.5-14B-Instruct
- gemma-3-4b
- gemma-3-1b-it
- ministral-3-3b
- ministral-3-14b-reasoning
I'm using LM Studio for model management and inference via the lms CLI utility, which worked perfectly in headless mode on Linux. On Mac, however, I couldn't get it to work completely headless - I had to install the app and open the UI at least once for the lms CLI to function correctly. Here is a video of it running the qwen model:

Hardware Specifications
| Platform | CPU/vCores | RAM | GPU |
|---|---|---|---|
| Linux VM | 8 vCores | 24 GB | None |
| Mac M2 | 8 Cores | 16 GB | 10 Cores |
| Mac Mini M4 | 10 Cores | 32 GB | 10 Cores |
1. Inference Performance
I was surprised by the inference speed on a CPU-only machine - the small qwen models (up to 3 billion parameters) performed quite well. When I last tested gemma models locally about 6 months ago, they were slower and worse in output quality than they are today.
Not surprisingly, there was a performance gap between CPU-only and the Mac. The CPU-only machine struggled with inference performance as the parameter count increased.
Tokens Per Second (TPS)
I used this prompt to measure the TPS:
Write a highly detailed, 1,500-word science fiction short story about a civilization living on a Dyson sphere. Focus on the engineering challenges they face and the daily life of a maintenance worker. Be extremely descriptive and do not summarize.
Results
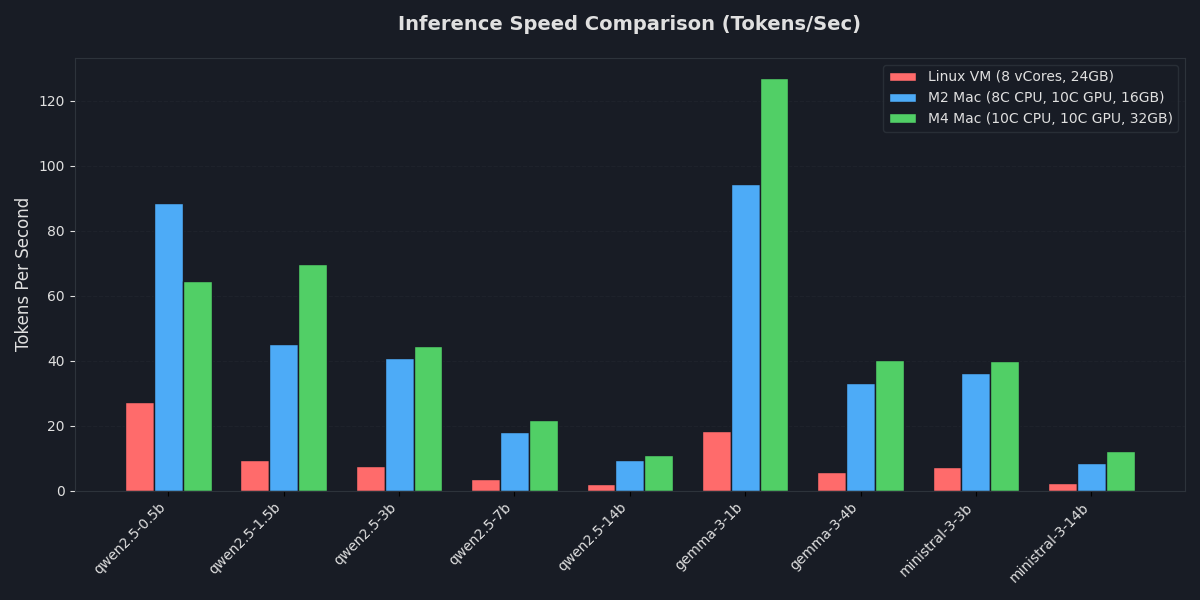
| Model | Linux CPU-only, TPS | M2 Mac (16GB RAM), TPS | M4 Mac (32GB RAM), TPS | Output | Quality of the generated story* |
|---|---|---|---|---|---|
| qwen2.5-0.5b | 27.39 | 88.46 | 64.53 | output.txt | 9 |
| qwen2.5-1.5b | 9.40 | 45.06 | 69.79 | output.txt | 7 |
| qwen2.5-3b | 7.42 | 40.83 | 44.40 | output.txt | 6 |
| qwen2.5-7b | 3.70 | 18.12 | 21.58 | output.txt | 5 |
| qwen2.5-14b | 1.99 | 9.29 | 10.98 | output.txt | 4 |
| gemma-3-1b | 18.45 | 94.40 | 126.96 | output.txt | 3 |
| gemma-3-4b | 5.67 | 33.21 | 40.25 | output.txt | 1 |
| ministral-3-3b | 7.28 | 36.32 | 39.84 | output.txt | 8 |
| ministral-3-14b | 2.24 | 8.51 | 12.14 | output.txt | 2 |
* The AI-storytelling quality for each model is ranked by a judge LLM (Gemini), with outputs scored from 1 (the winner) to 9 (the loser). Worth pointing out that none of the models reached the requested 1500-word count - most hovered between 800 and 1100 words.
Time to First Token (TTFT)
I used this prompt to measure the TTFT, basically I provided a long text and asked the model to process it and signal completion by outputting the word "READY" when finished.
Results
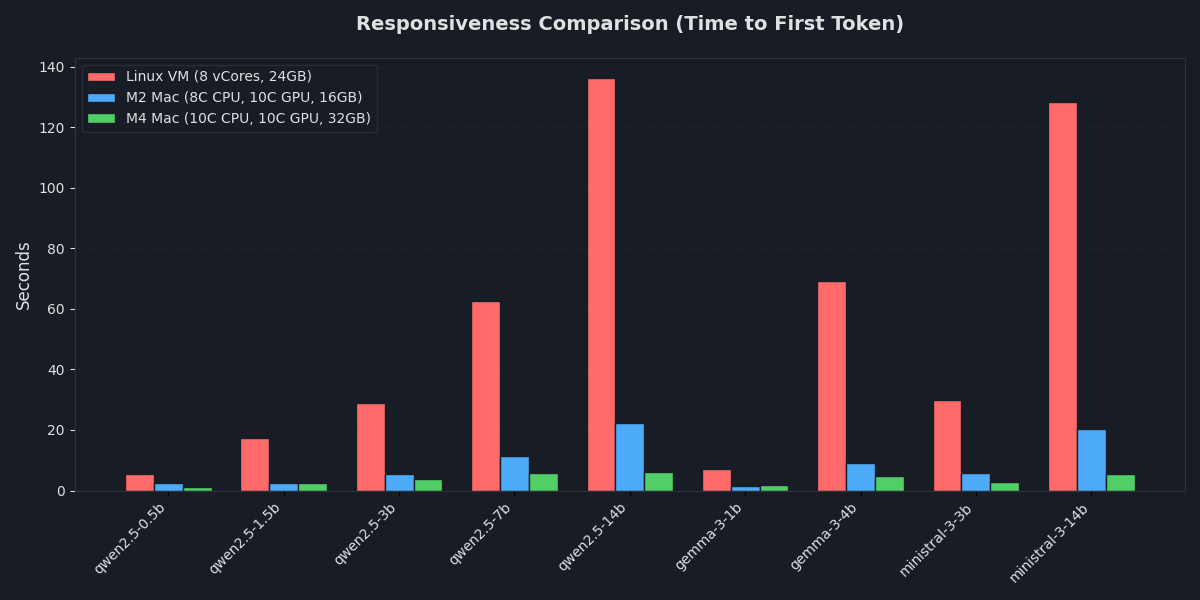
| Model | Linux CPU-only, seconds | M2 Mac (16GB RAM), seconds | M4 (32GB RAM), seconds |
|---|---|---|---|
| qwen2.5-0.5b | 5.449 | 2.442 | 1.116 |
| qwen2.5-1.5b | 17.484 | 2.391 | 2.522 |
| qwen2.5-3b | 28.946 | 5.350 | 3.927 |
| qwen2.5-7b | 62.468 | 11.533 | 5.847 |
| qwen2.5-14b | 136.175 | 22.253 | 6.057 |
| gemma-3-1b | 7.193 | 1.467 | 1.715 |
| gemma-3-4b | 69.297 | 9.161 | 4.903 |
| ministral-3-3b | 29.750 | 5.758 | 2.884 |
| ministral-3-14b | 128.380 | 20.225 | 5.554 |
On the CPU-only machine, I had to wait two minutes for the 14B models to start generating a response, whereas the M4 Mac provided nearly instant responses across the board.
2. Intelligence & Logic Test
I used the classic "Sally's Brothers" riddle to test reasoning:
Sally has 3 brothers. Each of her brothers has 2 sisters. How many sisters does Sally have?
There was a notable "intelligence jump" at the 3B-4B parameter mark. The result:
| Model Name | Result | Output Provided |
|---|---|---|
| qwen2.5-0.5b | ❌ Wrong | 5 sisters |
| qwen2.5-1.5b | ❌ Wrong | 5 sisters |
| qwen2.5-3b | ❌ Wrong | 5 sisters |
| qwen2.5-7b | ❌ Wrong | 5 sisters |
| qwen2.5-14b | ✅ Correct | 1 sister |
| gemma-3-1b | ❌ Wrong | 2 sisters |
| gemma-3-4b | ✅ Correct | 1 sister |
| ministral-3-3b | ✅ Correct | 1 sister |
| ministral-3-14b | ✅ Correct | 1 sister |
3. VRAM Pressure Test
I used this prompt to run a stress test - I asked the models to sumamrize a sufficiently long text into 10 bullet points. All models were able to complete the task on every machine. While it took a lot more time for bigger models to process the text, no crashes were expirinced.